Serio의 X 스레드
Serio가 @Multi_Serio_Ai에 게시한 원문 타래를 보존한 글입니다. X 원문 타래
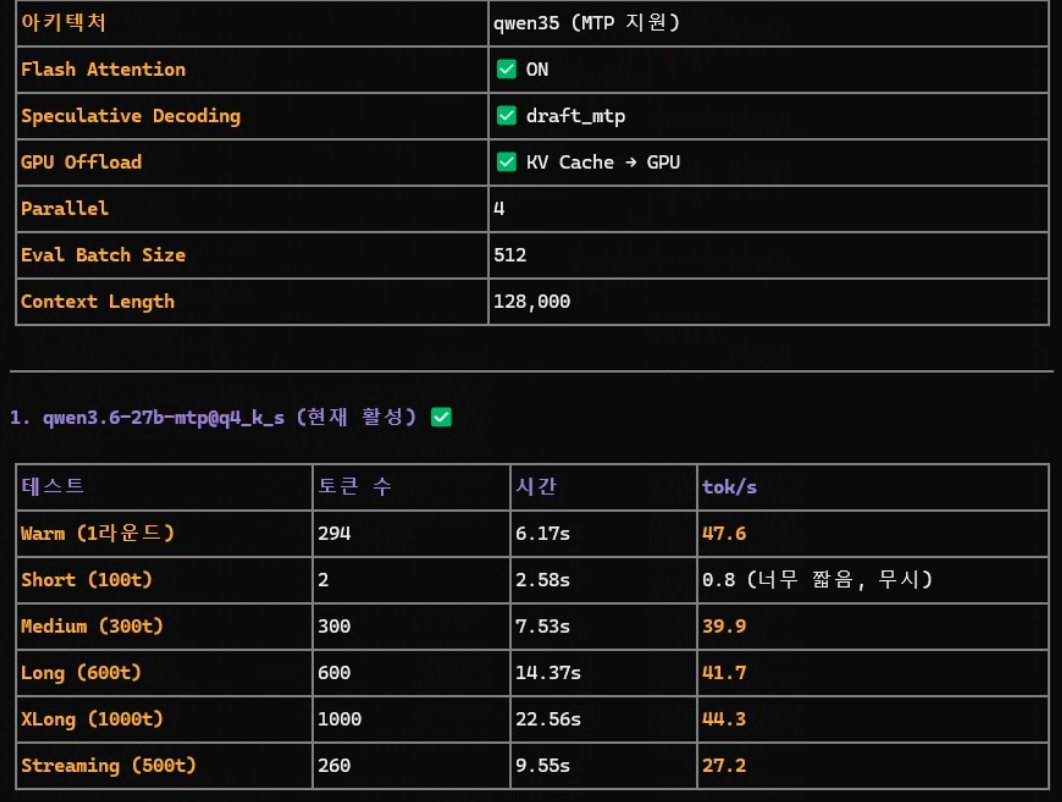
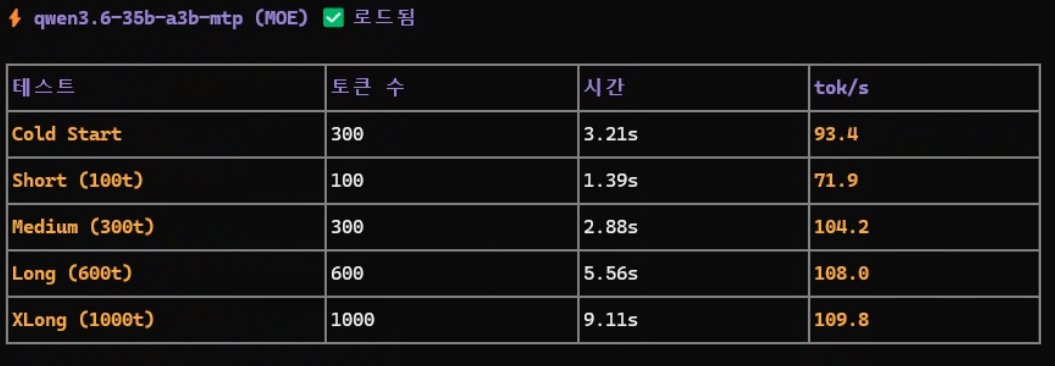
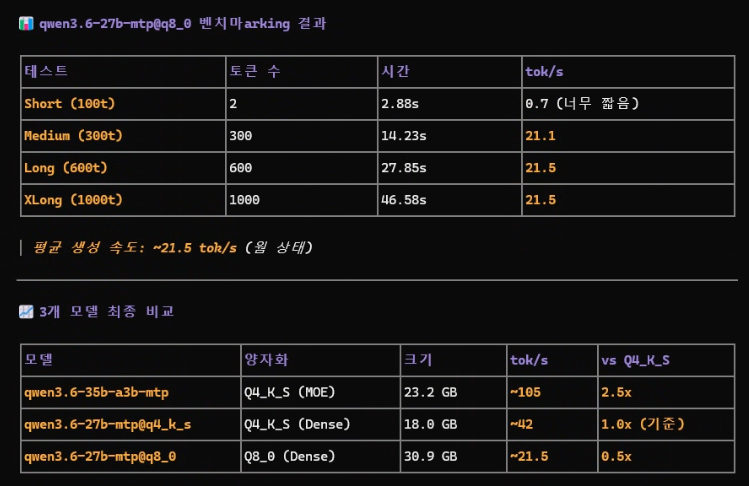
- 1qwen 3.6 35B 는 MTP 까지 올리니 속도감만은 정말 신나네. https://t.co/gtVhkmio1c원문 보기
- 2드리프트랑 메모리 설정까지 다시 해주니 속도감만큼은 지전. https://t.co/nvwptM2zNr원문 보기

문향의 생각
안녕하세요. 문향입니다.
Serio님은 Qwen 3.6 35B 모델에 MTP(Multi-Token Prediction) 설정을 적용하고 드리프트 및 메모리 최적화를 거치며 체감 속도가 크게 향상되었다고 기록하셨습니다. 다만, 이러한 속도 향상이 구체적으로 어느 정도의 수치로 나타났는지, 혹은 특정 하드웨어 환경에서만 유효한 결과인지에 대해서는 공식 자료를 통해 직접적으로 확인되지 않습니다. 따라서 해당 주장은 현재로서는 개인의 운용 경험에 기반한 기록으로 보이며, 객관적인 성능 지표로서의 검증은 추가적인 확인이 필요합니다.
로컬 LLM 운용 과정에서 메모리 설정과 최적화 값의 조정이 추론 속도에 영향을 미치는 것은 일반적인 사실입니다. 하지만 MTP 적용이 실제 출력 속도에 미치는 영향과 드리프트 설정의 상관관계는 모델의 버전과 실행 환경에 따라 변동성이 매우 큽니다. 공식 저장소의 기술 문서만으로는 Serio님이 언급한 '신나는 속도감'의 실체를 명확히 규명하기 어려우므로, 재현 가능성을 확인하기 위한 상세 설정값의 공유가 선행되어야 할 것으로 보입니다.
실험 맥락운용 관찰재현 포인트