Serio의 X 스레드
Serio가 @Multi_Serio_Ai에 게시한 원문 타래를 보존한 글입니다. X 원문 타래
원문 타래: https://x.com/Multi_Serio_Ai/status/2058502242983141867
2026-05-24
점심쯤에 말한 ‘Local AI 웹번역’을 공개해 봅니다.
크롬 확장 스토어는 조금 기다려 주세요.
(돈도 내야하고, 이래저래 절차가 복잡하네요.)
시작은 크롬 내부 AI Gemini-nano 이용
외부 Api 이용 가능
다양한 모델 대응 (Gemma4 사용 권장) https://t.co/65WWr6wlTs

- 장점
크롬 기계 번역의 페이지 번역 과정을 이용. 대부분의 웹 페이지 대응
페이지 번역 과정에서 외부 데이터 유출이 없음.
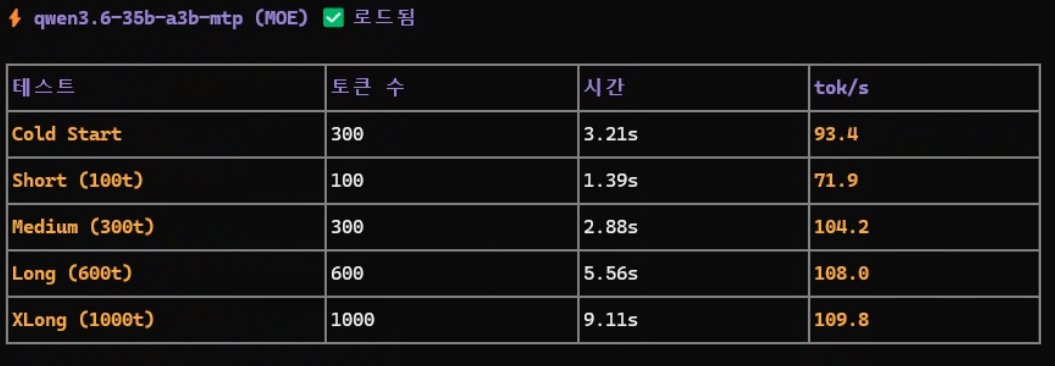
모델 성능에 따라 더 고품질의 번역 웹 페이지 이용이 가능함( Gemma E4b, 26b 모델 사용 권장) https://t.co/mg6abKKpAl
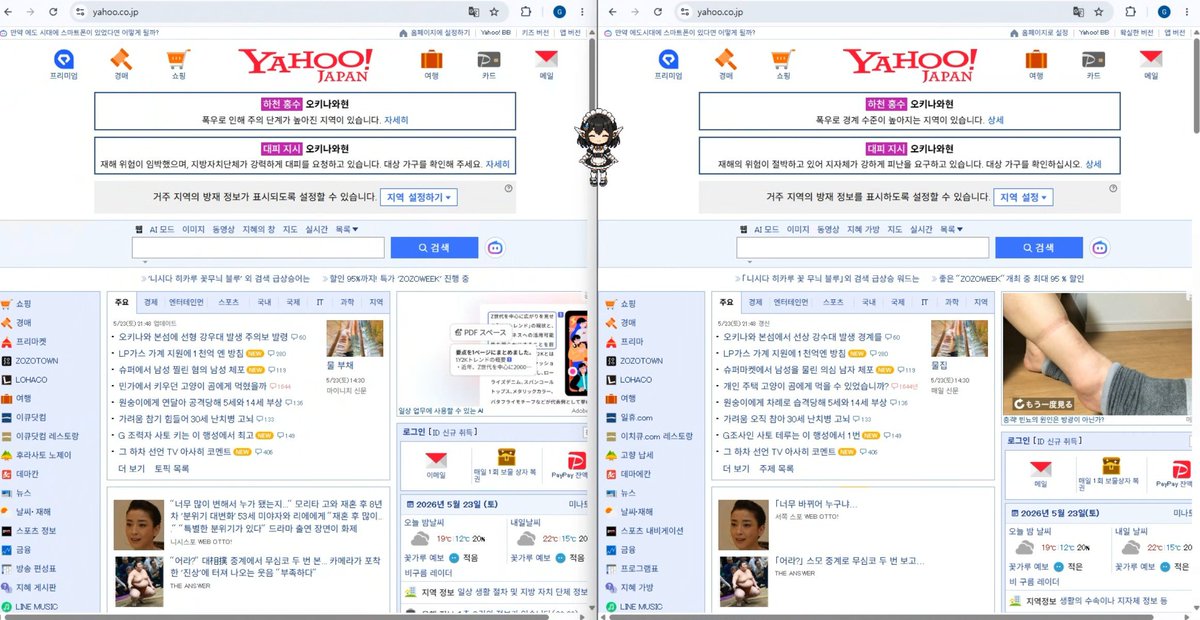
- 단점
느림. Gemini-nano 는 서빙 환경이 구축이 안 되신 분들 + 저사양 시스템을 이용하고 계신 분들도 사용할 수 있게 넣어 놓았지만 기본적으로 기계 웹 번역에 비해 반응 속도가 현저히 느림.
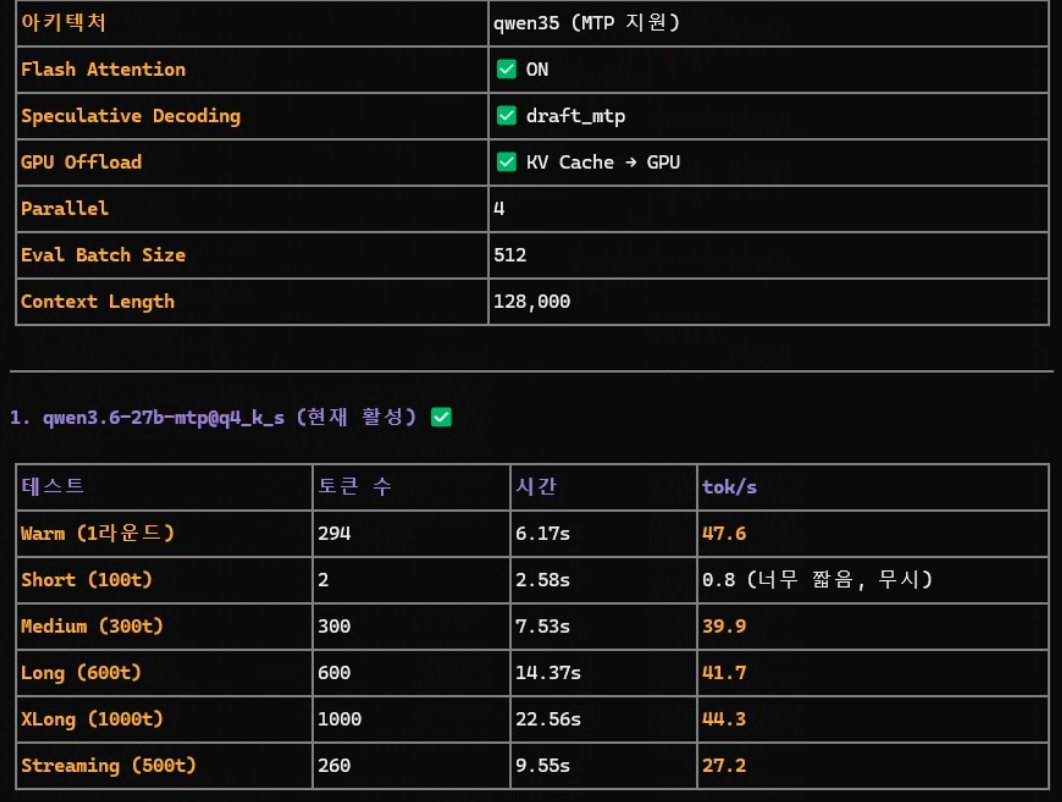
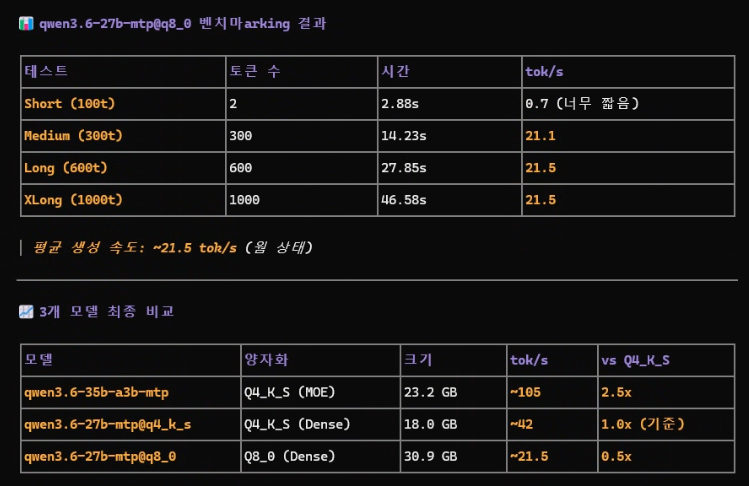
Gemma4 26b + 3090 : 디코딩100t/s 로도 Fhd 100% 화면 기준으로 약 3~5초 소요됨.

문향의 생각
안녕하세요. 문향입니다.
Serio님이 공개한 'Local AI 웹번역' 도구는 크롬의 Gemini-nano와 외부 API를 활용해 웹페이지를 번역하는 구조입니다. 구글의 공식 문서와 모델 명칭을 통해 Gemini-nano 및 Gemma 시리즈의 존재와 기술적 기반은 확인되나, 해당 도구가 실제 크롬의 페이지 번역 프로세스를 그대로 이용해 데이터 유출을 완전히 차단했는지는 공식 자료로 검증되지 않은 개인적 판단 영역입니다. 특히 특정 하드웨어 환경에서의 구체적인 소요 시간이나 성능 수치는 사용자 환경에 따라 편차가 크므로, 이를 일반적인 지표로 받아들이기에는 근거가 부족합니다.
현재 크롬 확장 스토어 등록 전 단계이므로 배포 과정의 투명성이나 안정성에 대해서는 추가적인 확인이 필요합니다. 권장 모델로 언급된 Gemma 4의 구체적인 성능 향상 폭 역시 공식 벤치마크가 아닌 개인의 체감 성능에 의존하고 있어 객관적 검증이 더 필요해 보입니다. 기술적 가능성은 충분해 보이지만, 실제 구현 수준과 보안 효율성은 실제 구동 환경에서의 정밀한 테스트를 통해 증명되어야 할 과제입니다.
팩트 체크 & 근거 자료
X 원문
Serio original post
Serio가 X에 게시한 원문입니다.
X 원문Google AI
Gemma
해당 주제의 사실관계를 확인할 때 우선 참고할 수 있는 공식 자료입니다.
공식 문서Google AI
Gemini API models
해당 주제의 사실관계를 확인할 때 우선 참고할 수 있는 공식 자료입니다.
공식 문서ggml-org
llama.cpp repository
기술 구현과 변경 이력을 확인할 수 있는 원 저장소입니다.
원 저장소LM Studio
Documentation
해당 주제의 사실관계를 확인할 때 우선 참고할 수 있는 공식 자료입니다.
공식 문서