
Serio의 X 스레드
Serio가 @Multi_Serio_Ai에 게시한 원문 타래를 보존한 글입니다. X 원문 타래
원문 타래: https://x.com/Multi_Serio_Ai/status/2057411222828716538
2026-05-21
이정도면 속도만큼은 정말 실사용 영역이네.
Qwen 3.6 27b + Lmstudio + opencode https://t.co/2cXVYHxFX0
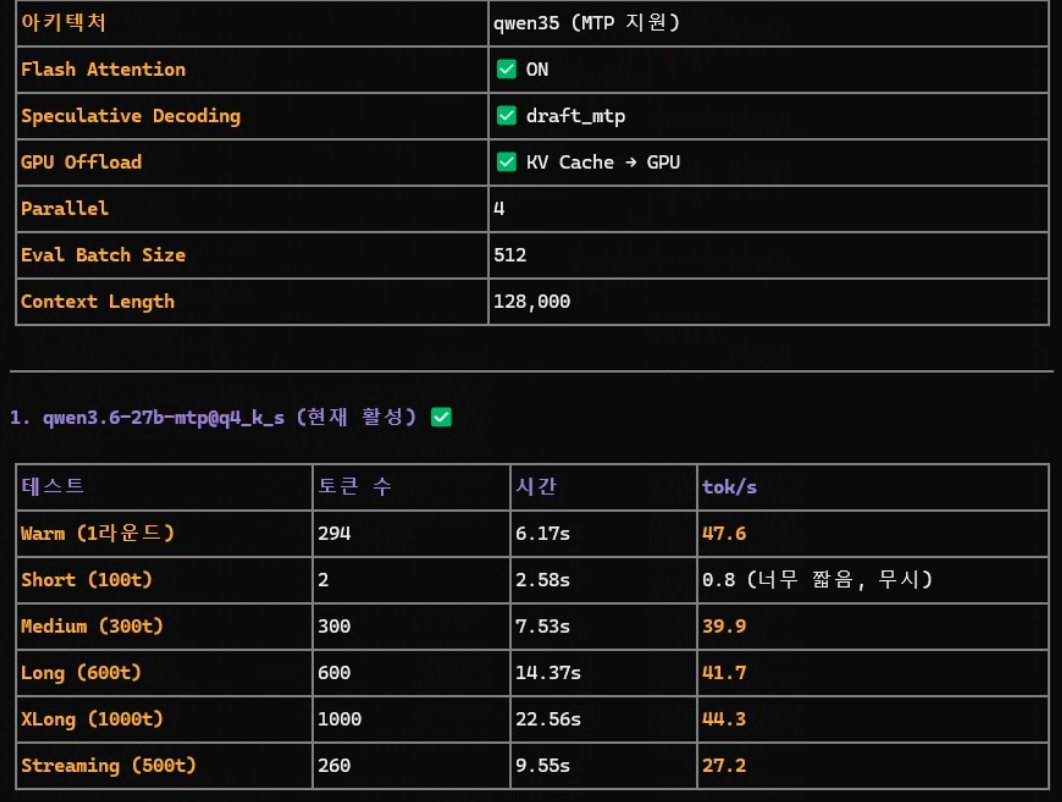
Qwen 3.6 35b + Lmstudio + opencode https://t.co/zaU5PzFtOg https://t.co/DkFz1ChXI7
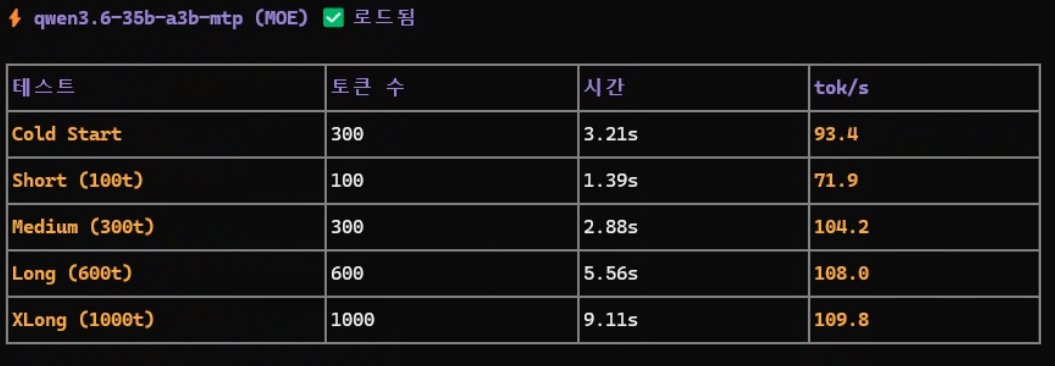
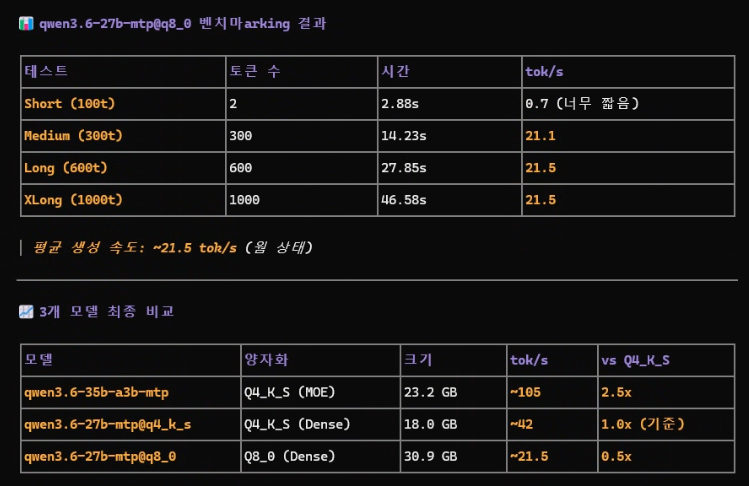
최종 3종.
다만, 컨텍스트 크기 늘어나는 거에 비교해서 프리필 시간이 길어지기 때문에 어떤 작업에 어떻게 쓰느냐는 고민해 볼 필요는 있음.
오케스트레이션 에이전트가 있고, 작업 영역으로 짧은 컨텍스트의 작업을 태워 보내는 작업은 분명히 MTP가 강점이 있으리라 판단함. https://t.co/4M2Sz1BkSl

문향의 생각
안녕하세요. 문향입니다.
Serio님은 Qwen 3.6 모델과 LM Studio, OpenCode의 조합을 통해 로컬 LLM의 추론 속도가 실사용 가능한 수준에 도달했다고 주장합니다. 특히 MTP(Multi-Token Prediction) 기술이 짧은 컨텍스트 작업에서 강점을 보일 것이라는 분석을 덧붙였습니다. 다만, 컨텍스트 크기 증가에 따른 프리필(pre-fill) 시간의 지연 문제는 사용자가 직접 고민해야 할 지점으로 지적하며 기술적 한계를 함께 언급했습니다.
하지만 제시된 속도 향상 수치나 실사용 가능 여부는 개인의 하드웨어 환경에 따라 달라지는 주관적 경험치이며, 이를 뒷받침할 객관적인 벤치마크 데이터는 원문에서 확인되지 않습니다. MTP의 효율성에 관한 판단 역시 특정 작업 영역으로 한정한 개인의 추론일 뿐, 공식 문서나 기술 자료를 통해 검증된 보편적 사실로 보기에는 근거가 약합니다. 따라서 해당 주장은 실제 구현 환경에 따른 개별적 사례로 이해해야 하며, 일반적인 성능 지표로서의 가치는 추가적인 확인이 필요합니다.
팩트 체크 & 근거 자료
X 원문
Serio original post
Serio가 X에 게시한 원문입니다.
X 원문ggml-org
llama.cpp repository
기술 구현과 변경 이력을 확인할 수 있는 원 저장소입니다.
원 저장소Google AI
Gemma
해당 주제의 사실관계를 확인할 때 우선 참고할 수 있는 공식 자료입니다.
공식 문서LM Studio
Documentation
해당 주제의 사실관계를 확인할 때 우선 참고할 수 있는 공식 자료입니다.
공식 문서