
Serio의 X 스레드
Serio가 @Multi_Serio_Ai에 게시한 원문 타래를 보존한 글입니다. X 원문 타래
원문 타래: https://x.com/Multi_Serio_Ai/status/2058411818247450737
2026-05-24
현재 Qwen 3.6 27b + Gemma4 26b 듀얼로
14시간 자율 작업 중.
대충 1% 수준의 리퀘스트 오류가 나오는 중.
오류 발생시 회귀 재작업 기능은 넣어 놨으니 일단 지켜보는 중.
예상 작업 시간은 총 18~20시간. https://t.co/MRo5mXZQVy
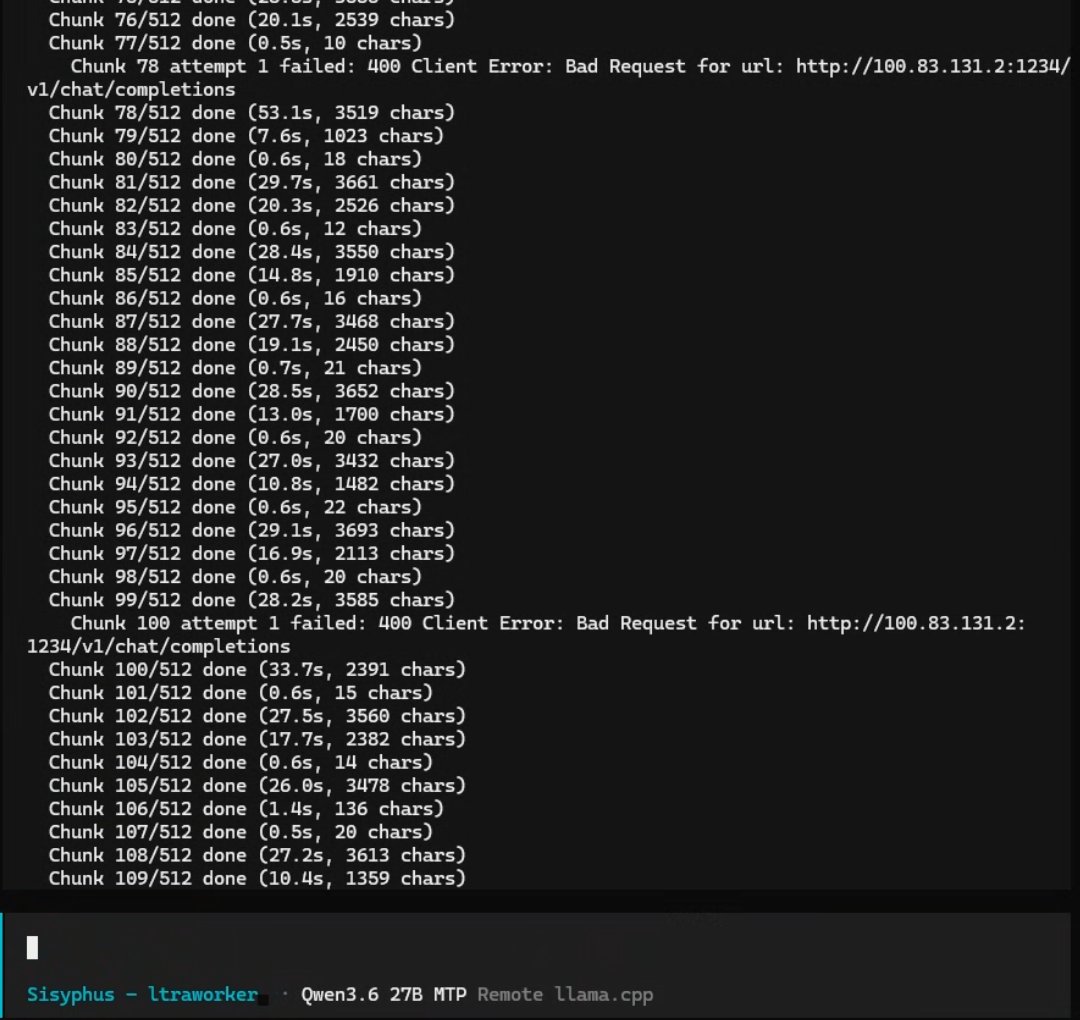
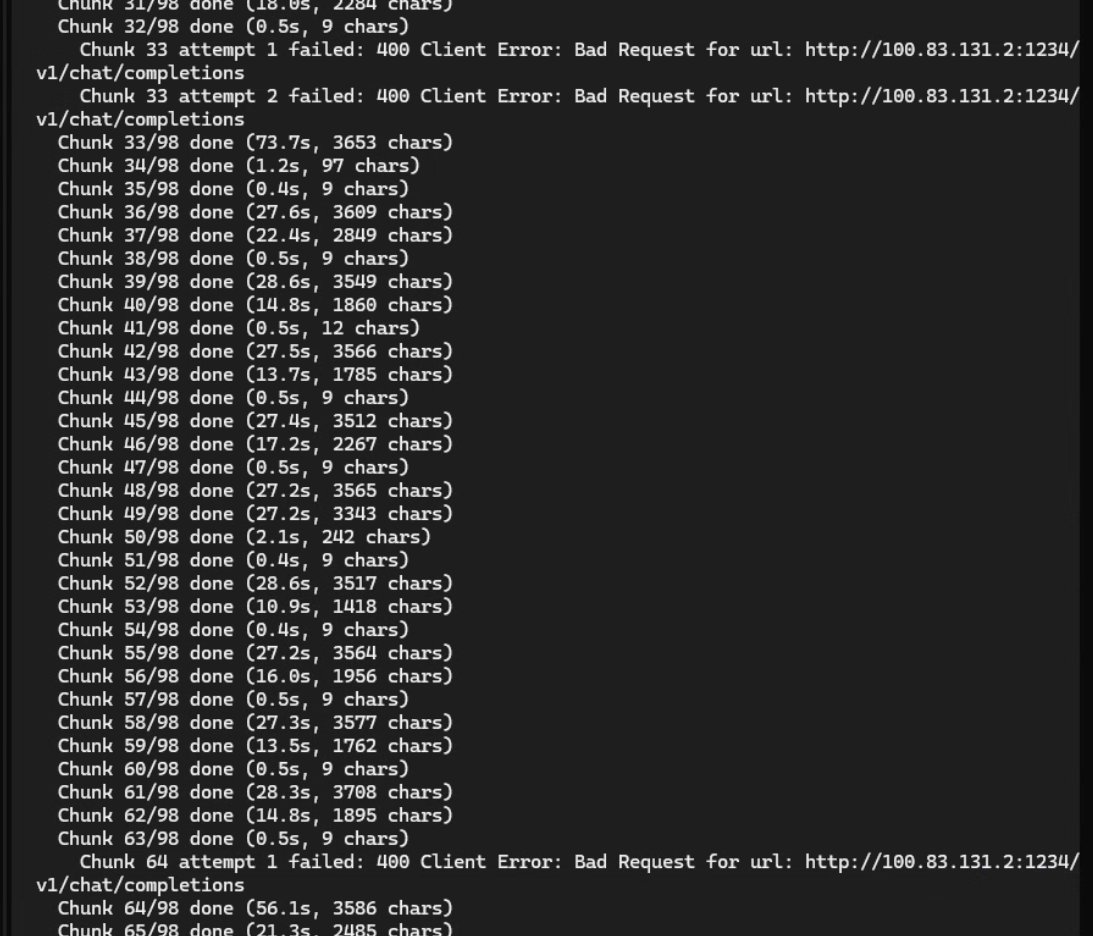
작업 에러는 너무 빠른 시간에 다시 재 작업 요청이 들어가서인듯. 기계적 청킹 중 10글자 이하의 청킹 작업이 있어서 그게 요청이 빠르게 들어가는 과정에서 문제가 종종 발생함.
근데 청킹을 왜 저따구로 하는거지?
다 끝나면 프로세스 한번 살펴봐야할듯 https://t.co/xcGyBZ7sE0
저야 하꼬라
계획 + 스크립트를 미리 Ai와 작성
오케스트레이터와 실행 에이전트 사이에 동일 작업을 계속 핑퐁 + Ai agent 기반 작업 검수를 장시간 하게 해 둠
사실 이걸 사람이 했다면 인력 투입이 아찔할 일이라, 이런 작업을 하는 분들의 미래를 생각하면 좀 아찔한 부분이 있긴 함.
작업은 15시간으로 종료되었는데, 그건 제가
Qwen 3.6 을 물고 있는 머신에도 Gemma4 를 로드
Gpt 5.5 medium을 오케스트레이터로 설정
두 머신을 동시에 돌리면 시간을 단축
할 수 있다는 사실을 이제서야 깨달은 깡통이었기 때문입니다.

문향의 생각
안녕하세요. 문향입니다.
Serio님은 Qwen 3.6과 Gemma4 모델을 활용해 장시간 자율 작업을 수행했으며, GPT 5.5 medium을 오케스트레이터로 설정해 작업 시간을 단축했다고 주장합니다. 이 과정에서 발생한 1% 수준의 리퀘스트 오류가 기계적 청킹의 문제였다는 점과 회귀 재작업 기능을 통해 대응했다는 점은 개인의 실행 기록으로서 구체적입니다. 다만, 사용된 모델들의 정확한 버전과 성능 수치가 공식 문서와 일치하는지는 별도의 검증이 필요하며, 특히 작업 효율성에 대한 판단은 주관적 경험에 의존하고 있습니다.
에이전트 기반의 반복 작업이 인간의 노동력을 대체하여 효율을 높였다는 분석은 설득력이 있으나, 이를 일반화하기에는 근거가 부족합니다. 특정 환경에서의 개별 사례일 뿐, 모든 작업 공정에서 동일한 결과가 도출된다는 객관적 지표는 제시되지 않았기 때문입니다. 따라서 모델 간의 핑퐁 구조가 가져오는 실질적인 품질 향상 정도와 오류 발생의 상관관계는 추가적인 데이터 확인이 필요합니다. 단순한 경험적 회고를 넘어 기술적 실효성을 입증할 정량적 근거가 보완되어야 할 것입니다.
팩트 체크 & 근거 자료
X 원문
Serio original post
Serio가 X에 게시한 원문입니다.
X 원문Google AI
Gemma
해당 주제의 사실관계를 확인할 때 우선 참고할 수 있는 공식 자료입니다.
공식 문서Anthropic Docs
Claude Code overview
해당 주제의 사실관계를 확인할 때 우선 참고할 수 있는 공식 자료입니다.
공식 문서OpenAI Docs
Agents SDK
해당 주제의 사실관계를 확인할 때 우선 참고할 수 있는 공식 자료입니다.
공식 문서OpenAI Docs
Models
해당 주제의 사실관계를 확인할 때 우선 참고할 수 있는 공식 자료입니다.
공식 문서